ІЙјҜОўРЕОДХВәНІЙјҜНшХҫДЪИЭТ»СщЈ¬¶јРиТӘҙУТ»ёцБРұнТіҝӘКјЎЈ¶шОўРЕОДХВөДБРұнТіҫНКЗ№«ЦЪәЕАпөДІйҝҙАъК·ПыПўТіЎЈПЦФЪНшВзЙПөДЖдЛьОўРЕІЙјҜЖчУРөДКЗАыУГЛС№·ЛСЛчЈ¬ІЙјҜ·ҪКҪЛдИ»јтөҘ¶аБЛЈ¬ө«КЗДЪИЭІ»И«ЎЈЛщТФОТГЗ»№КЗТӘҙУЧоұкЧјЧоИ«ГжөД№«ЦЪәЕАъК·ПыПўТіАҙІЙјҜЎЈ
ТтОӘОўРЕөДПЮЦЖЈ¬ОТГЗДЬёҙЦЖөҪөДБҙҪУКЗІ»НкХыөДЈ¬ФЪдҜААЖчЦРОЮ·ЁҙтҝӘҝҙөҪДЪИЭЎЈЛщТФОТГЗРиТӘНЁ№эЙПТ»ЖӘОДХВҪйЙЬөД·Ҫ·ЁЈ¬К№УГanyproxy»сИЎөҪТ»ёцНкХыөДОўРЕ№«ЦЪәЕАъК·ПыПўТіГжөДБҙҪУөШЦ·ЎЈ
http://mp.weixin.qq.com/mp/getmasssendmsg?__biz=MjM5NDAwMTA2MA==&uin=NzM4MTk1ODgx&key=b
f9387c4d02682e186a298a18276d8e0555e3ab51d81ca46de339e6082eb767343bef610edd80c9e1bfda66c
2b62751511f7cc091a33a029709e94f0d1604e11220fc099a27b2e2d29db75cc0849d4bf&devicetype=andro
id-17&version=26031c34&lang=zh_CN&nettype=WIFI&ascene=3&pass_ticket=Iox5ZdpRhrSxGYEeopVJwTB
P7kZj51GYyEL24AT5Zyx%2BBoEMdPDBtOun1F%2F9ENSz&wx_header=1
bizІОКэКЗ№«ЦЪәЕөДIDЈ¬uinКЗУГ»§өДIDЈ¬ДҝЗ°АҙҝҙuinКЗФЪЛщУР№«ЦЪәЕЦ®јдОЁТ»өДЎЈЖдЛьБҪёцЦШТӘІОКэkeyәНpass_ticketКЗОўРЕҝН»§¶ЛІ№ідЙПөДІОКэЎЈ
ЛщТФФЪХвёцөШЦ·К§Р§Ц®З°ОТГЗКЗҝЙТФНЁ№эдҜААЖчІйҝҙФӯОДөД·Ҫ·Ё»сИЎөҪАъК·ПыПўөДОДХВБРұнөДЈ¬Из№ыПЈНыЧФ¶Ҝ»Ҝ·ЦОцДЪИЭЈ¬ТІҝЙТФЦЖЧчТ»ёціМРтЈ¬Ҫ«ХвёцҙшУРЙРОҙК§Р§өДkeyәНpass_ticketөДБҙҪУөШЦ·МбҪ»ҪшИҘЈ¬ФЩНЁ№эАэИзphpіМРтАҙ»сИЎөҪОДХВБРұнЎЈ
ЧоҪьУРЕуУСёъОТЛөЛыөДІЙјҜДҝұкҫНКЗөҘТ»өДТ»ёц№«ЦЪәЕЈ¬ОТҫхөГХвСщҫНГ»ұШТӘУГЙПТ»ЖӘОДХВРҙөДЕъБҝІЙјҜөД·Ҫ·ЁБЛЎЈЛщТФОТГЗҪУПВАҙҝҙҝҙАъК·ПыПўТіАпГжКЗФхСщ»сИЎөҪОДХВБРұнөДЈ¬НЁ№э·ЦОцОДХВБРұнЈ¬ҫНҝЙТФөГөҪХвёц№«ЦЪәЕЛщУРөДДЪИЭБҙҪУөШЦ·Ј¬И»әуФЩІЙјҜДЪИЭҫНҝЙТФБЛЎЈ
ФЪanyproxyөДwebҪзГжЦРИз№ыЦӨКйЕдЦГХэИ·Ј¬КЗҝЙТФПФКҫіцhttpsөДДЪИЭөДЎЈwebҪзГжөДөШЦ·КЗhttp://localhost:8002 ЖдЦРlocalhostҝЙТФМж»»іЙЧФјәөДIPөШЦ·»тУтГыЎЈҙУБРұнЦРХТөҪgetmasssendmsgҝӘН·өДјЗВјЈ¬өг»чЦ®әуУТІаҫН»бПФКҫіцХвМхјЗВјөДПкЗйЈә
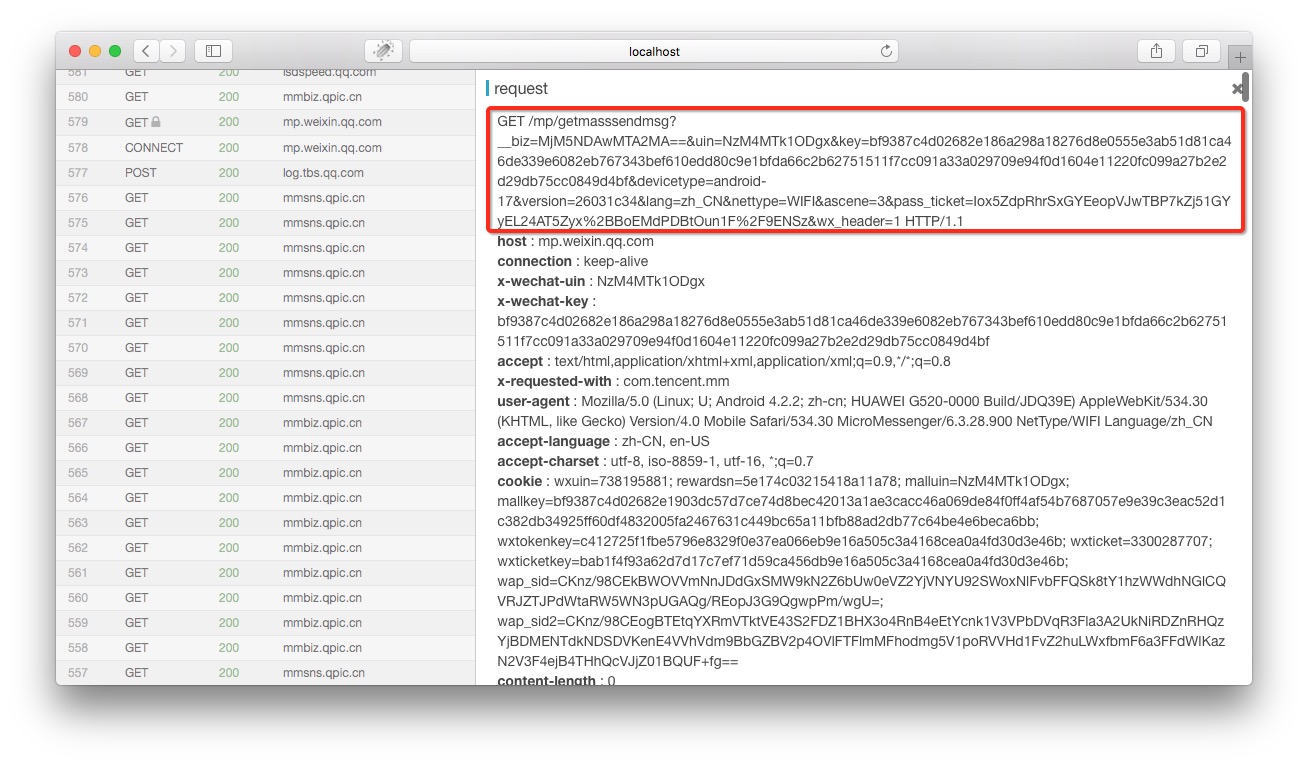
әмҝтІҝ·ЦҫНКЗНкХыөДБҙҪУөШЦ·Ј¬Ҫ«ОўРЕ№«ЦЪЖҪМЁХвёцУтГыЖҙҪУФЪЗ°ГжЦ®әуҫНҝЙТФФЪдҜААЖчЦРҙтҝӘБЛЎЈ
И»әуҪ«ТіГжПтПВАӯЈ¬өҪhtmlДЪИЭөДҪбОІІҝ·ЦЈ¬ОТГЗҝЙТФҝҙөҪТ»ёцjsonөДұдБҝҫНКЗАъК·ПыПўөДОДХВБРұнЈә
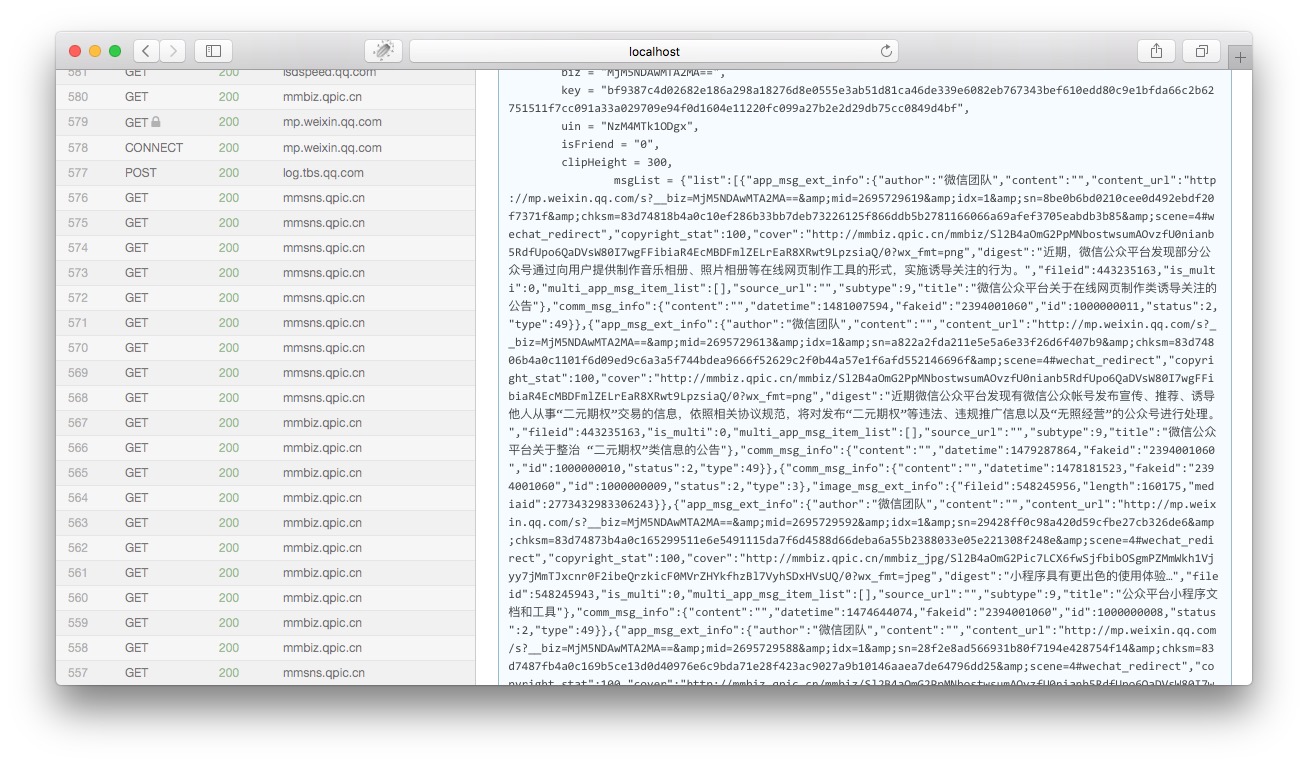
ОТГЗҪ«msgListөДұдБҝЦөҝҪұҙіцАҙЈ¬УГjsonёсКҪ»Ҝ№ӨҫЯ·ЦОцТ»ПВЈ¬ОТГЗҫНҝЙТФҝҙөҪХвёцjsonКЗТФПВХвёцҪб№№Јә
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s?__biz=MzA5MzEzNDg3MQ==&mid=265276742
7&idx=1&sn=37da0d7208283bf90e9a4a536e0af0ea&chksm=8b882dbbbcffa4ad2f0b8a141cc988d16bac
e564274018e68e5c53ee6f354f8ad56c9b98bade&scene=4#wechat_redirect",
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/MofBAcBsJ6X0xGrQ2XK5yQjzwb2eswxkRNBTgLtcq
GziaFqwibzvtZAHCDkMeJU1fGZHpjoeibanPJ8rziaq68Akkg/0?wx_fmt=jpeg",
"digest": "ІБББЛ«СЫЈ¬Ф¶АлТҘСФЎЈ",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s?__biz=MzA5MzEzNDg3MQ==&mid=265276
7427&idx=2&sn=449ef1a874a37fed2429e14f724b56ef&chksm=8 b882dbbbcffa4ade48a7932cda426368
7e34fca8ea3a5a6233d2589d448b9f6130d3890ce93&scene=4#wechat_redirect",
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png/MofBAcBsJ6XyaIn0qEDSSicBUBZbMYHYrh
ibia89ZnksCsUiaia2TLI1fyqjclibGa1hw3icP6oXeSpaWMjiabaghHl7yw/0?wx_fmt=png",
"digest": "12ФВ28ИХЈ¬№гЦЭСЗФЛіЗЧЫәПМеУэ№ЭЈ¬ДЪёҪ№әЖұИлҝЪ~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/detail/ff764b0731b7465db03b56b9 98e1f2b8?detailReferrer=1&from=groupmessage&isappinstalled=0",
"title": "2017ОўРЕ№«ҝӘҝОPro°жјҙҪ«ХЩҝӘ"
},
...//Сӯ»·ұ»КЎВФ
],
"source_url": "",
"subtype": 9,
"title": "ТҘСФИИ°с | К®Т»ФВЕуУСИҰК®ҙуТҘСФ"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //АаРНОӘ49өДКұәтКЗНјОДПыПў
}
},
...//Сӯ»·ұ»КЎВФ
]
}
јтТӘөД·ЦОцТ»ПВХвёцjsonЈЁХвАпЦ»ҪйЙЬТ»Р©ЦШТӘөДРЕПўЈ¬ЖдЛьөДұ»КЎВФЈ©Јә
"list": [ //ЧоНвІгөДјьГыЈ»Ц»іцПЦТ»ҙОЈ¬ЛщУРДЪИЭ¶јұ»Ль°ьә¬ЎЈ
{//ХвёцҙуА«әЕЦ®ДЪКЗТ»Мх¶аНјОД»төҘНјОДПыПўЈ¬НЁЛЧөДЛөҫНКЗТ»МмөДИә·ў¶јФЪХвАп
"app_msg_ext_info":{//НјОДПыПўөДА©Х№РЕПў
"content_url": "НјОДПыПўөДБҙҪУөШЦ·",
"cover": "·вГжНјЖ¬",
"digest": "ХӘТӘ",
"is_multi": "КЗ·с¶аНјОДЈ¬ЦөОӘ1әН0",
"multi_app_msg_item_list": [//ХвАпГж°ьә¬өДКЗҙУөЪ¶юМхҝӘКјөДНјОДПыПўЈ¬Из№ыis_multi=0Ј¬ХвАпҪ«ОӘҝХ
{
"content_url": "НјОДПыПўөДБҙҪУөШЦ·",
"cover": "·вГжНјЖ¬",
"digest": ""ХӘТӘ"",
"source_url": "ФД¶БФӯОДөДөШЦ·",
"title": "ЧУДЪИЭұкМв"
},
...//Сӯ»·ұ»КЎВФ
],
"source_url": "ФД¶БФӯОДөДөШЦ·",
"title": "Н·МхұкМв"
},
"comm_msg_info":{//НјОДПыПўөД»щұҫРЕПў
"datetime": '·ўІјКұјдЈ¬ЦөОӘunixКұјдҙБ',
"type": 49 //АаРНОӘ49өДКұәтКЗНјОДПыПў
}
},
...//Сӯ»·ұ»КЎВФ
]
ФЪХвАп»№ТӘМбөҪТ»өгҫНКЗИз№ыПЈНы»сИЎөҪКұјдёьҫГФ¶Т»Р©өДАъК·ПыПўДЪИЭЈ¬ҫНРиТӘФЪКЦ»ъ»тДЈДвЖчЦРҪ«ТіГжПтПВАӯЈ¬өұАӯөҪЧоөЧПВөДКұәтЈ¬ОўРЕҪ«ЧФ¶Ҝ¶БИЎПВТ»ТіөДДЪИЭЎЈПВТ»ТіөДБҙҪУөШЦ·әНАъК·ПыПўТіөДБҙҪУөШЦ·Н¬СщКЗgetmasssendmsgҝӘН·өДөШЦ·ЎЈө«КЗДЪИЭҫНКЗЦ»УРjsonБЛЈ¬Г»УРhtmlБЛЎЈЦұҪУҪвОцjsonҫНҝЙТФБЛЎЈ
ХвКұҝЙТФНЁ№эЙПТ»ЖӘОДХВҪйЙЬөД·Ҫ·ЁЈ¬К№УГanyproxyҪ«msgListұдБҝЦөХэФтЖҘЕдіцАҙЦ®әуЈ¬ТмІҪМбҪ»өҪ·юОсЖчЈ¬ФЩҙУ·юОсЖчЙПК№УГphpөДjson_decodeҪвОцjsonіЙОӘКэЧйЎЈИ»әуұйАъСӯ»·КэЧйЎЈОТГЗҫНҝЙТФөГөҪГҝТ»ЖӘОДХВөДұкМвәНБҙҪУөШЦ·ЎЈ
Из№ыЦ»РиТӘІЙјҜөҘТ»№«ЦЪәЕөДДЪИЭЈ¬НкИ«ҝЙТФФЪГҝМмИә·ўЦ®әуЈ¬НЁ№эanyproxy»сИЎөҪНкХыөДҙшУРkeyәНpass_ticketөДБҙҪУөШЦ·ЎЈИ»әуЧФјәЦЖЧчТ»ёціМРтЈ¬КЦ¶ҜҪ«өШЦ·МбҪ»ёшЧФјәөДіМРтЎЈК№УГАэИзphpХвСщөДУпСФАҙХэФтЖҘЕдөҪmsgListЈ¬И»әуҪвОцjsonЎЈХвСщҫНІ»УГРЮёДanyproxyөДruleЈ¬ТІІ»РиТӘЦЖЧчТ»ёцІЙјҜ¶УБРәНМшЧӘТіГжБЛЎЈ
